

一、OneReward模型介绍
OneReward 是一种基于Qwen2.5-VL生成式奖励模型的全新视觉领域RLHF方法,通过增强多任务强化学习显著提升策略模型在多项子任务中的生成能力。基于OneReward,开发出Seedream 3.0 Fill 统一图像编辑模型,能高效处理图像填充、延展、物体消除和文字渲染等多样化任务,其表现超越Ideogram、Adobe Photoshop和FLUX Fill [Pro]等多家顶尖商业与开源系统。最后,基于FLUX Fill [dev]版本,我们激动地发布FLUX.1-Fill-dev-OneReward,该模型在修补与扩展绘画任务上性能优于闭源的FLUX Fill [Pro],为未来统一图像编辑研究树立了强大的新基准。
模型功能:
- 图像填充(Image Fill):在指定区域内根据文本生成内容,考验的是文本对齐和结构合理性。
- 图像扩展(Image Extend):在图像外部生成内容,考验的是美学和风格一致性。
- 对象移除(Object Removal):无痕地抹除物体,考验的是纹理一致性和移除质量。
- 文字渲染(Text Rendering):准确地在图中生成文字,考验的是文字渲染准确率。

二、插件安装
无需安装插件
官方地址:
github:https://github.com/bytedance/OneReward
项目主页:https://one-reward.github.io/
huggingface:https://huggingface.co/bytedance-research/OneReward
===============
模型路径:
ComfyUI/
├── models/
│ ├── lora/
│ │ └── removal_timestep_alpha-2.safetensors
│ └── unet/
│ └── fill-dev-OneReward-bf8.safetensors
│ └── fill-dev-OneReward-bf16.safetensors
三、工作流效果及体验
局部重绘 | OneReward_Fill

OneReward_Fill 扩图重绘:更精准扩图

Seedream 3.0 Fill:统一编辑模型的强大实力
下图直观展示了Seedream 3.0 Fill在四大编辑场景中的能力,无论是复杂的图像填充、自然的场景扩展、干净的物体移除,还是精准的文字渲染,模型都表现得游刃有余。
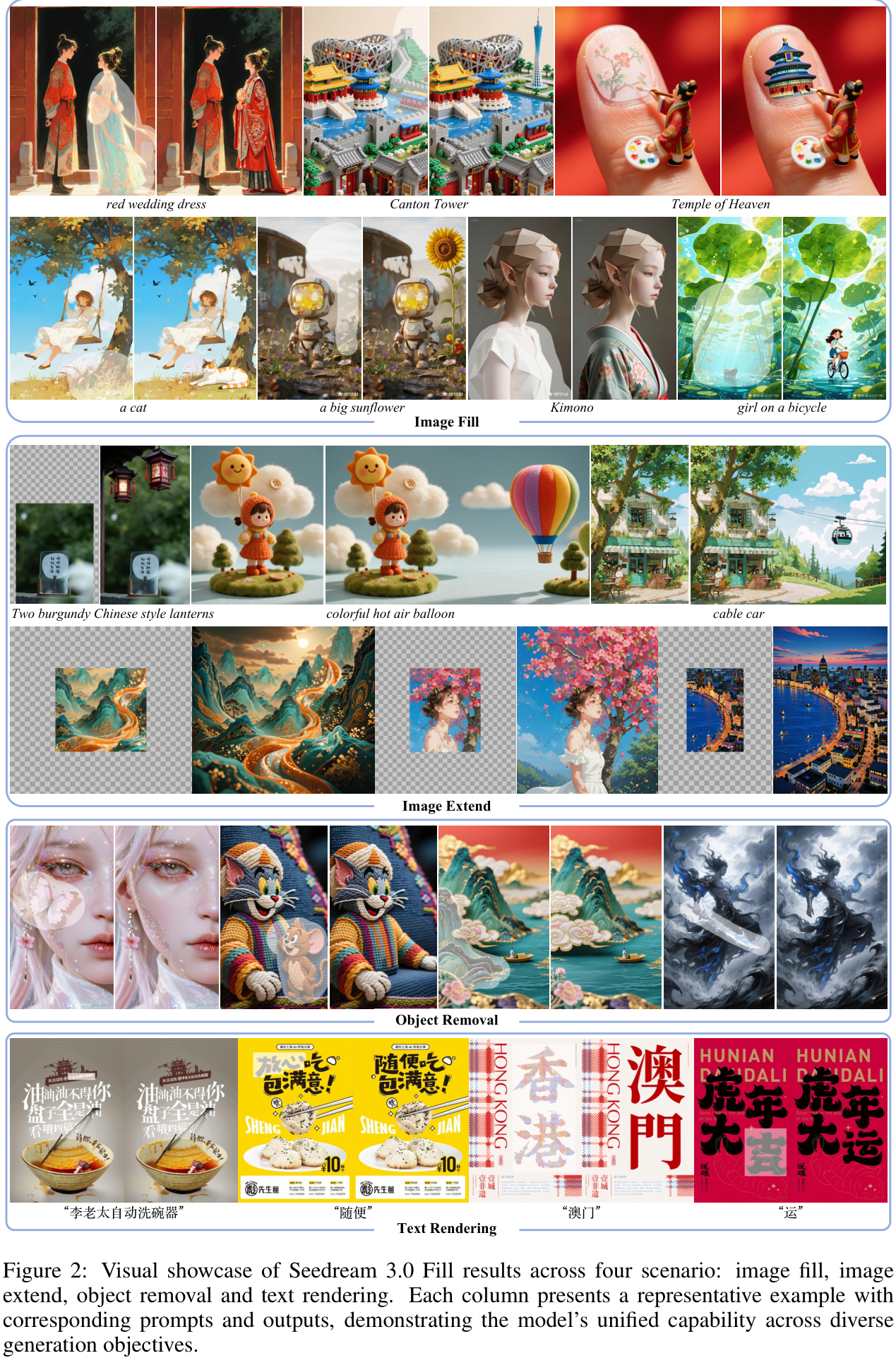
总结与贡献
OneReward的提出,为解决多任务生成模型的训练困境提供了一个极具开创性的思路。其核心贡献在于:
- 提出了OneReward框架:一个新颖、统一的强化学习框架,通过单个VLM奖励模型,实现了对多任务、多评价维度的统一优化。
- 验证了RL替代SFT的可行性:成功证明了可以直接在预训练模型上通过多任务强化学习进行优化,完全绕过繁琐且低效的任务特定SFT,为未来生成模型的训练范式提供了新思路。
- 打造了SOTA统一编辑模型:基于该框架开发的Seedream 3.0 Fill,在多个任务上全面超越现有商业和开源方案,展示了该框架的巨大潜力。
- 全面开源:团队将开源模型和代码,为社区研究和应用统一生成模型提供了宝贵的资源。
OneReward的思路极具启发性,它将VLM的语言理解能力巧妙地转化为可泛化的奖励信号,优雅地解决了多任务学习中的核心矛盾。这不仅对图像编辑领域,对其他需要进行多目标优化的生成任务(如视频、3D等)也具有重要的借鉴意义。